
…or why I always recommend using the LPCM audio recording format to capture your research data. And there are many audio recording formats, but we are going to focus on the mp3 and the WAV/LPCM recording formats. Why? Because these two format are currently the most popular audio recording format that you’ll find on most digital voice recorders. Also WAV and mp3 recording formats are great, ubiquitous examples of compressed and uncompressed audio recording formats.
But before we get to that. Let’s first lay the foundation for understanding audio formats. And for that we need to understand 3 key features of recorded audio; sampling rate, bit depth, and bit rate. And since this is a basic guide to understanding audio recording format, I’ll also briefly touch on audio channels (mono vs stereo) and digital sound quantization.
Audio Channels; Mono vs Stereo
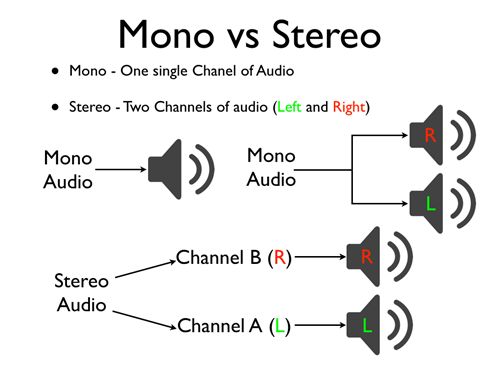
The easiest way to understand audio channels is to think of tracks or traffic lanes. Where mono represents one (1) track and stereo two (2) tracks. So when recording in mono, you are recording audio into a single track. When recording in stereo, you are recording audio into two tracks; left and right. Now, for you to truly have a stereo recording, you are going to need two or more microphones. You cannot record a stereo track using one microphone. True stereo sound requires multiple inputs. You can create a stereo track from a mono recording, but it’s just doubling the audio (and increasing the volume) to left and right channel. It will sound the same as the mono recording.
Should you record in mono or stereo? I get this question a lot and I’m normally hesitant to answer it. Because, it depends on a lot of factors. But my rule of thumb is this; if you have multiple microphones, record in stereo. If you have one microphone, record in mono (or stereo – it doesn’t matter!) The only advantage of recording in mono, when you have one microphone, is your audio file is only half the size of a stereo recording. So you can save storage space by recording audio in mono.
Now, all the recorders that I recommend you use to record your interviews, focus groups, lectures, meetings etc come with two (2) microphones. The Sony ICD-PX470 and Sony ICD-ux560 allow you to record a mono recording using the MP3 48kbps recording format. There’s no reason for you to use this format to record your research data because both of those recorders come with ample storage space that enables you to record your data using a better recording format, which are all stereo (even when you attach an external microphone).
Which leads to my final tip. If you’re using an external microphone, which I recommend you do when you are in a noisy location, you’ll want to use a microphone with a stereo jack (TRS). Why? If you use a microphone with a mono TS jack (if you’re confused, this is a great post on microphone jacks) you are likely to record static on the right stereo channel. Now, you can edit this out in post-production, but it’s better to use a mic that outputs a “fake” stereo and save yourself the trouble of having unwanted noise in your recording.
Quantization
The word “quantization” sounds complicated, but what it boils down to is the process of assigning a numerical value to something—giving it a quantity. In audio recording, this is important because sound is propagated (transmitted) as a wave and requires a medium (air, gas, solid) to be transmitted, and thus it’s transmitted as an analog wave: a continuous difference in air pressure etc. Turning this analog signal into digital (discrete) signal/data requires quantization.
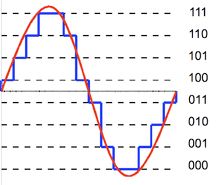
3 bit depth
Why am I geeking out on you? Because everything we’re going to henceforth talk about is quantization, or how we record an analog signal (sound) into binary (digital) data. And that it. That’s how we digitally record/play sound. And it does help that talking about quantization is a great segue into understanding the three basic features of digital audio: sampling rate, bit depth, and bit rate.
Sampling Rate
From our previous discussion, you might have realized that quantitation is approximation. Hence, we need to determine beforehand, how many samples we are going to take. We can’t sample infinitely, because we’ll have infinite data, what we want is finite data. Simply put, audio sampling rate is the number of samples we collect per unit of time (seconds). And the de facto audio sampling rate is 44,100 samples per second. You’ll find this denoted as 44,100 Hertz (Hertz is the SI unit for cycles per second or, for the rest of us, number of times per second).
Why is 44,100 Hertz (short form 44.1 kHz) the most commonly used audio sampling frequency? Because the Shannon-Nyquist sampling theorem, which states that a sampled signal can only capture frequencies equal to half its sample rate. So the highest frequency that can be reproduced by a 44.1 kHz audio file is 22,050Hz. Not coincidentally, this is just slightly higher than the highest proven range of human hearing. Since we only care about what we can hear, we only need to sample at double the highest range of human hearing.
Now, you can record audio using a higher sampling rate. For instance, using the Zoom H1n, you can record audio using the 48 kHz and 96 kHz sampling rate (popular sampling rates for broadcast audio). Will you be able to notice the difference in the quality of the recorded audio? Probably not. I’ve found that the 44.1 kHz sampling is more than adequate for recording research data.
Bit Depth
Using the audio sampling rate, we have determined the number of samples we are going to take per second for our approximation of the analog sound signal. However, we’ve yet to determine how precise our samples are going to be. Obviously, more precision equal a more accurate approximation of the analog sound that leads to better recorded digital sound. Now, the precision of each audio sample is called bit depth.
The most popular bit depth used to record audio is 16 bit, which is 65536 possible values (216 = 65536). So for each audio sample, and remember there are 44.1 samples taken per second, there are 65536 possible values. That’s very precise.
However, using the Zoom H1n, you can record audio using a 24 bit audio format. That’s 224 = 16, 777, 216 possible values! Over 16 million possible values per audio sample! That level of precision is simply incredible. I’ve found 16 bit to be more than sufficient for recording audio interview, focus groups, lectures, meetings etc.
Bit Rate
If you’ve understood audio sampling rate (number of samples) and audio bit depth (sample precision), understanding audio bit rate is relatively easy. Because, audio bit rate is the number of bits recorded per second. In other words, the amount of data (in bits) transmitted (encoded/decoded) in a second: bits per second.
Now we already know the number of samples taken per second (sampling rate) and the number of bits per sample (bit depth). So Bits Per Second (bps) = Sample Rate (Hz) x Bit Depth (bits) x Channel Count. For stereo audio recorded using the 44.1 kHz sampling rate and 16 bit bit depth, the bit rate is 44,100 x 16 x 2 (two channels in stereo recording) = 1,411,200 bits per second.
Bit rate is an important measure. It’s how you know how much storage space you need for your audio. For instance, if you are planning to record an hour long interview using the 44.1 kHz, 16 bit recording format, you are going to need at least 636 MBs (megabytes) plus addition space for the audio container (wav, etc). Bit rate also tells you how much bandwidth you are going to need/use when streaming audio video (yes, videos have a bit rate).
Anyway, this discussion on bitrate is a great way to also talk about compressed and uncompressed audio. And why I always recommend that you record you research data using the 44.1 kHz/16-bit WAV recording format.
Compressed vs Uncompressed Audio
We’ve discussed the basic features of all digital audio stream: sample rate and bit depth. And this is the standard form for digital audio in computer, recorders, phones etc. This basic form is known as Pulse-code modulation (PCM). Linear pulse-code modulation (LPCM) is a specific type of PCM where the quantization levels (sampling rate and bit depth) are linearly uniform. We’ve been discussing LPCM audio!
Now, audio is stored/transmitted using standard file formats to ensure compatibility. Waveform Audio File Format, simply WAV, is one of the most popular uncompressed audio file format. And MPEG-2 Audio Layer III, simply mp3, is a popular compressed audio file format. There’re a lot of other compressed and uncompressed file formats, but we’re going to restrict our discussion to wav and mp3 because these are the two format that you are going to encounter when recording audio using a digital recorder.
MP3 vs WAV
As earlier stated mp3 is a compressed audio format. And it’s actually a very good audio compression format. That is, it has a very good tradeoff of the amount of data transmitted/stored and sound quality. Interestingly, in the mp3 file format, quantization is performed on the frequency domain representation of the signal (using 576 frequency bins), not on the time domain samples relevant to bit depth.
And, while the 44.1 kHz sampling rate is commonly used for mp3s, a bit depth is not set. Instead, a target bit rate is set and compression is optimized at the set bit rate. For instance, in a 192 kbps (this is a bit rate of 192,000 bits per second, or 192 kilobits per second) mp3 file, the compression algorithm is set to achieve a goal of 192 kbps audio stream. If you want to know more about mp3 compression, read this.
Why use the mp3 audio recording format? The main reason is file size. A 44.1 kHz, 192 kbps mp3 audio file is about 7 times smaller than its uncompressed wav counterpart. That’s a huge reduction is file size. And you’ll be hard pressed to notice a difference in audio quality between 44.1 kHz/192 kbps mp3 and a 44.1 kHz/16 bit wav. So, recording in mp3 format, you’ll get a file that’s 7 times smaller and almost similar sound quality! That’s an excellent trade off. In addition, mp3 is a very well supported file format. So you’ll be able to share and play it on most devices, especially smart phones and tablets.
However, the target bit rate, quality of the mp3 encoder algorithm, as well as the complexity of the signal being encoded affect audio quality of the recorded audio. But more importantly, if you edit an mp3 file or convert it to another format you’ll notice a huge drop in the quality of the audio recording. Here’s why.
Why Choose WAV over MP3
When you edit or convert (to a different format mp3 or another file format) an audio file the audio software has to first convert the mp3 file into a raw LPCM format: decode the audio file. That enables you to edit the audio file – edit out the beginning and/or ending of the interview et al. Once you’ve edited the file, the raw audio is then converted into your desired audio format. There’s lot of approximation (quantization) in decoding/encoding compressed audio files – and that’s why there’s a noticeable loss of audio quality when you edit/convert mp3 audio files.
And there’s nothing that you can do to mitigate this loss of quality. You cannot magically recreate information that’s not there. This is the greatest disadvantage of compressed audio. And that’s why I always recommend that you record your research data using the uncompressed WAV file format. Because, if you ever need to edit or convert the audio file, you’ll always have pristine quality audio file to work from.
What sampling frequency and bit depth should you use when recording interviews, focus group discussion? I recommend that you use the 44.1 kHz sampling rate and 16 bit depth: what’s commonly known as CD quality audio. You’ll get a high quality LPCM quality audio recording and manageable audio file sizes.
That’s it for this post on understanding audio recording format. Sorry it’s so dense (believe me, I tried to make is as simple as possible) and long! I hope you’ve found it useful. If you have any questions/suggestions, please post them in the comment section below. Happy recording. And remember to consider us for all of your academic transcription needs.
Thank you sir for your indepth knowlege of audio recording of natural world. This will help in my research further
This was a very well taught, short lesson. I thoroughly enjoyed the way in which you presented information, laid it out, and taught it throughout your article.
Might be worth mentioning FLAC. Smaller file size than LPCM WAV, but bit-perfect unlike MP3.
My issue with FLAC is that the compression is at best 0.5x.
Never understood why anyone would spend time and effort to compress audio using FLAC to save 50% of the space.
If you want small fize size, use mp3, if you want lossless quality, keep it as a WAV file.
My 2 cents.
Is there any website to correct these parameters because I have a sample that I need to upload soon and need to check all of these requirements :
24 bit, 44 kHz, mono
Unprocessed, RAW .wav
-60dB noise floor (or better)
Not sure if there are websites that can do this for you – but there are softwares…